Lineage
DataHub’s Python SDK allows you to programmatically define and retrieve lineage between metadata entities. With the DataHub Lineage SDK, you can:
- Add table-level and column-level lineage across datasets, data jobs, dashboards, and charts
- Automatically infer lineage from SQL queries
- Read lineage (upstream or downstream) for a given entity or column
- Filter lineage results using structured filters
Getting Started
To use DataHub SDK, you'll need to install acryl-datahub and set up a connection to your DataHub instance. Follow the installation guide to get started.
Connect to your DataHub instance:
from datahub.sdk import DataHubClient
client = DataHubClient(server="<your_server>", token="<your_token>")
- server: The URL of your DataHub GMS server
- local:
http://localhost:8080 - hosted:
https://<your_datahub_url>/gms
- local:
- token: You'll need to generate a Personal Access Token from your DataHub instance.
Add Lineage
The add_lineage() method allows you to define lineage between two entities.
Add Entity Lineage
You can create lineage between two datasets, data jobs, dashboards, or charts. The upstream and downstream parameters should be the URNs of the entities you want to link.
Add Entity Lineage Between Datasets
# Inlined from /metadata-ingestion/examples/library/lineage_dataset_add.py
from datahub.metadata.urns import DatasetUrn
from datahub.sdk.main_client import DataHubClient
client = DataHubClient.from_env()
upstream_urn = DatasetUrn(platform="snowflake", name="sales_raw")
downstream_urn = DatasetUrn(platform="snowflake", name="sales_cleaned")
client.lineage.add_lineage(upstream=upstream_urn, downstream=downstream_urn)
Add Entity Lineage Between Datajobs
# Inlined from /metadata-ingestion/examples/library/lineage_datajob_to_datajob.py
from datahub.metadata.urns import DataFlowUrn, DataJobUrn
from datahub.sdk import DataHubClient
client = DataHubClient.from_env()
dataflow_urn = DataFlowUrn(
orchestrator="airflow", flow_id="data_pipeline", cluster="PROD"
)
client.lineage.add_lineage(
upstream=DataJobUrn(flow=dataflow_urn, job_id="data_job_1"),
downstream=DataJobUrn(flow=dataflow_urn, job_id="data_job_2"),
)
For supported lineage combinations, see Supported Lineage Combinations.
Add Column Lineage
You can add column-level lineage by using column_lineage parameter when linking datasets.
Add Column Lineage with Fuzzy Matching
# Inlined from /metadata-ingestion/examples/library/lineage_dataset_column.py
from datahub.metadata.urns import DatasetUrn
from datahub.sdk import DataHubClient
client = DataHubClient.from_env()
client.lineage.add_lineage(
upstream=DatasetUrn(platform="snowflake", name="sales_raw"),
downstream=DatasetUrn(platform="snowflake", name="sales_cleaned"),
column_lineage=True, # same as "auto_fuzzy", which maps columns based on name similarity
)
When column_lineage is set to True, DataHub will automatically map columns based on their names, allowing for fuzzy matching. This is useful when upstream and downstream datasets have similar but not identical column names. (e.g. customer_id in upstream and CustomerId in downstream). See Column Lineage Options for more details.
Add Column Lineage with Strict Matching
# Inlined from /metadata-ingestion/examples/library/lineage_dataset_column_auto_strict.py
from datahub.metadata.urns import DatasetUrn
from datahub.sdk import DataHubClient
client = DataHubClient.from_env()
client.lineage.add_lineage(
upstream=DatasetUrn(platform="snowflake", name="sales_raw"),
downstream=DatasetUrn(platform="snowflake", name="sales_cleaned"),
column_lineage="auto_strict",
)
This will create column-level lineage with strict matching, meaning the column names must match exactly between upstream and downstream datasets.
Add Column Lineage with Custom Mapping
For custom mapping, you can use a dictionary where keys are downstream column names and values represent lists of upstream column names. This allows you to specify complex relationships.
# Inlined from /metadata-ingestion/examples/library/lineage_dataset_column_custom_mapping.py
from datahub.metadata.urns import DatasetUrn
from datahub.sdk import DataHubClient
client = DataHubClient.from_env()
client.lineage.add_lineage(
upstream=DatasetUrn(platform="snowflake", name="sales_raw"),
downstream=DatasetUrn(platform="snowflake", name="sales_cleaned"),
# { downstream_column -> [upstream_columns] }
column_lineage={
"id": ["id"],
"region": ["region", "region_id"],
"total_revenue": ["revenue"],
},
)
Infer Lineage from SQL
You can infer lineage directly from a SQL query using infer_lineage_from_sql(). This will parse the query, determine upstream and downstream datasets, and automatically add lineage (including column-level lineage when possible) and a query node showing the SQL transformation logic.
# Inlined from /metadata-ingestion/examples/library/lineage_dataset_from_sql.py
from datahub.sdk.main_client import DataHubClient
client = DataHubClient.from_env()
sql_query = """
CREATE TABLE sales_summary AS
SELECT
p.product_name,
c.customer_segment,
SUM(s.quantity) as total_quantity,
SUM(s.amount) as total_sales
FROM sales s
JOIN products p ON s.product_id = p.id
JOIN customers c ON s.customer_id = c.id
GROUP BY p.product_name, c.customer_segment
"""
# sales_summary will be assumed to be in the default db/schema
# e.g. prod_db.public.sales_summary
client.lineage.infer_lineage_from_sql(
query_text=sql_query,
platform="snowflake",
default_db="prod_db",
default_schema="public",
)
Check out more information on how we handle SQL parsing below.
Add Query Node with Lineage
If you provide a transformation_text to add_lineage, DataHub will create a query node that represents the transformation logic. This is useful for tracking how data is transformed between datasets.
# Inlined from /metadata-ingestion/examples/library/lineage_dataset_add_with_query_node.py
from datahub.metadata.urns import DatasetUrn
from datahub.sdk.main_client import DataHubClient
client = DataHubClient.from_env()
upstream_urn = DatasetUrn(platform="snowflake", name="upstream_table")
downstream_urn = DatasetUrn(platform="snowflake", name="downstream_table")
transformation_text = """
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("HighValueFilter").getOrCreate()
df = spark.read.table("customers")
high_value = df.filter("lifetime_value > 10000")
high_value.write.saveAsTable("high_value_customers")
"""
client.lineage.add_lineage(
upstream=upstream_urn,
downstream=downstream_urn,
transformation_text=transformation_text,
column_lineage={"id": ["id", "customer_id"]},
)
# by passing the transformation_text, the query node will be created with the table level lineage.
# transformation_text can be any transformation logic e.g. a spark job, an airflow DAG, python script, etc.
# if you have a SQL query, we recommend using add_dataset_lineage_from_sql instead.
# note that transformation_text itself will not create a column level lineage.
Transformation text can be any transformation logic, Python scripts, Airflow DAG code, or any other code that describes how the upstream dataset is transformed into the downstream dataset.
Providing transformation_text will NOT create column lineage. You need to specify column_lineage parameter to enable column-level lineage.
If you have a SQL query that describes the transformation, you can use infer_lineage_from_sql to automatically parse the query and add column level lineage.
Get Lineage
The get_lineage() method allows you to retrieve lineage for a given entity.
Get Entity Lineage
Get Upstream Lineage for a Dataset
This will return the direct upstream entity that the dataset depends on. By default, it retrieves only the immediate upstream entities (1 hop).
# Inlined from /metadata-ingestion/examples/library/lineage_get_basic.py
from datahub.metadata.urns import DatasetUrn
from datahub.sdk.main_client import DataHubClient
client = DataHubClient.from_env()
downstream_lineage = client.lineage.get_lineage(
source_urn=DatasetUrn(platform="snowflake", name="sales_summary"),
direction="downstream",
)
print(downstream_lineage)
Get Downstream Lineage for a Dataset Across Multiple Hops
To get upstream/downstream entities that are more than one hop away, you can use the max_hops parameter. This allows you to traverse the lineage graph up to a specified number of hops.
# Inlined from /metadata-ingestion/examples/library/lineage_get_with_hops.py
from datahub.metadata.urns import DatasetUrn
from datahub.sdk.main_client import DataHubClient
client = DataHubClient.from_env()
downstream_lineage = client.lineage.get_lineage(
source_urn=DatasetUrn(platform="snowflake", name="sales_summary"),
direction="downstream",
max_hops=2,
)
print(downstream_lineage)
if you provide max_hops greater than 2, it will traverse the full lineage graph and limit the results by count.
Return Type
get_lineage() returns a list of LineageResult objects.
results = [
LineageResult(
urn="urn:li:dataset:(urn:li:dataPlatform:snowflake,table_2,PROD)",
type="DATASET",
hops=1,
direction="downstream",
platform="snowflake",
name="table_2", # name of the entity
paths=[] # Only populated for column-level lineage
)
]
Get Column-Level Lineage
Get Downstream Lineage for a Dataset Column
You can retrieve column-level lineage by specifying the source_column parameter. This will return lineage paths that include the specified column.
# Inlined from /metadata-ingestion/examples/library/lineage_column_get.py
from datahub.metadata.urns import DatasetUrn
from datahub.sdk.main_client import DataHubClient
client = DataHubClient.from_env()
# Get column lineage for the entire flow
# you can pass source_urn and source_column to get lineage for a specific column
# alternatively, you can pass schemaFieldUrn to source_urn.
# e.g. source_urn="urn:li:schemaField:(urn:li:dataset:(urn:li:dataPlatform:snowflake,downstream_table),id)"
downstream_column_lineage = client.lineage.get_lineage(
source_urn=DatasetUrn(platform="snowflake", name="sales_summary"),
source_column="id",
direction="downstream",
)
print(downstream_column_lineage)
You can also pass SchemaFieldUrn as the source_urn to get column-level lineage.
# Inlined from /metadata-ingestion/examples/library/lineage_column_get_from_schemafield.py
from datahub.sdk.main_client import DataHubClient
client = DataHubClient.from_env()
# Get column lineage for the entire flow
results = client.lineage.get_lineage(
source_urn="urn:li:schemaField:(urn:li:dataset:(urn:li:dataPlatform:snowflake,sales_summary,PROD),id)",
direction="downstream",
)
print(list(results))
Return type
The return type is the same as for entity lineage, but with additional paths field that contains column lineage paths.
results = [
LineageResult(
urn="urn:li:dataset:(urn:li:dataPlatform:snowflake,table_2,PROD)",
type="DATASET",
hops=1,
direction="downstream",
platform="snowflake",
name="table_2", # name of the entity
paths=[
LineagePath(
urn="urn:li:schemaField:(urn:li:dataset:(urn:li:dataPlatform:snowflake,table_1,PROD),col1)",
column_name="col1", # name of the column
entity_name="table_1", # name of the entity that contains the column
),
LineagePath(
urn="urn:li:schemaField:(urn:li:dataset:(urn:li:dataPlatform:snowflake,table_2,PROD),col4)",
column_name="col4", # name of the column
entity_name="table_2", # name of the entity that contains the column
)
] # Only populated for column-level lineage
)
]
For more details on how to interpret the results, see Interpreting Lineage Results.
Filter Lineage Results
You can filter by platform, type, domain, environment, and more.
# Inlined from /metadata-ingestion/examples/library/lineage_get_with_filter.py
from datahub.sdk.main_client import DataHubClient
from datahub.sdk.search_filters import FilterDsl as F
client = DataHubClient.from_env()
# get upstream snowflake production datasets.
results = client.lineage.get_lineage(
source_urn="urn:li:dataset:(platform,sales_agg,PROD)",
direction="upstream",
filter=F.and_(F.platform("snowflake"), F.entity_type("dataset"), F.env("PROD")),
)
print(results)
You can check more details about the available filters in the Search SDK documentation.
Lineage SDK Reference
For a full reference, see the lineage SDK reference.
Supported Lineage Combinations
The Lineage APIs support the following entity combinations:
| Upstream Entity | Downstream Entity |
|---|---|
| Dataset | Dataset |
| Dataset | DataJob |
| DataJob | DataJob |
| DataJob | Dataset |
| Dataset | Dashboard |
| Chart | Dashboard |
| Dashboard | Dashboard |
| Dataset | Chart |
ℹ️ Column-level lineage and creating query node with transformation text are only supported for
Dataset → Datasetlineage.
Column Lineage Options
For dataset-to-dataset lineage, you can specify column_lineage parameter in add_lineage() in several ways:
| Value | Description |
|---|---|
False | Disable column-level lineage (default) |
True | Enable column-level lineage with automatic mapping (same as "auto_fuzzy") |
"auto_fuzzy" | Enable column-level lineage with fuzzy matching (useful for similar column names) |
"auto_strict" | Enable column-level lineage with strict matching (exact column names required) |
| Column Mapping | A dictionary mapping downstream column names to lists of upstream column names |
auto_fuzzy vs auto_strictauto_fuzzy: Automatically matches columns based on similar names, allowing for some flexibility in naming conventions. For example, these two columns would be considered a match:- user_id → userId
- customer_id → CustomerId
auto_strict: Requires exact column name matches between upstream and downstream datasets. For example,customer_idin the upstream dataset must matchcustomer_idin the downstream dataset exactly.
Interpreting Column Lineage Results
When retrieving column-level lineage, the results include paths that show how columns are related across datasets. Each path is a list of column URNs that represent the lineage from the source column to the target column.
For example, let's say we have the following lineage across three tables:
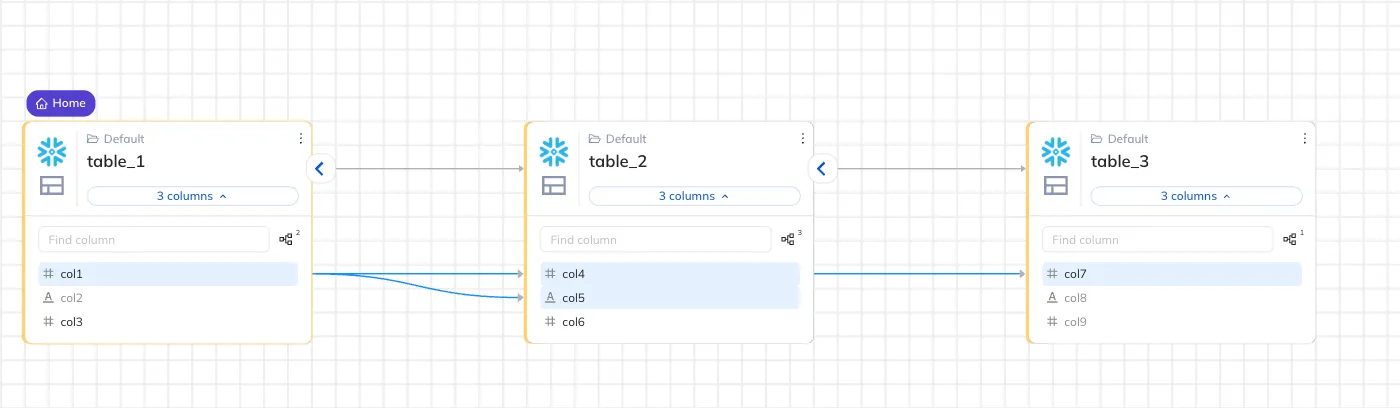
Example with max_hops=1
>>> client.lineage.get_lineage(
source_urn="urn:li:dataset:(urn:li:dataPlatform:snowflake,table_1,PROD)",
source_column="col1",
direction="downstream",
max_hops=1
)
Returns:
[
{
"urn": "...table_2...",
"hops": 1,
"paths": [
["...table_1.col1", "...table_2.col4"],
["...table_1.col1", "...table_2.col5"]
]
}
]
Example with max_hops=2
>>> client.lineage.get_lineage(
source_urn="urn:li:dataset:(urn:li:dataPlatform:snowflake,table_1,PROD)",
source_column="col1",
direction="downstream",
max_hops=2
)
Returns:
[
{
"urn": "...table_2...",
"hops": 1,
"paths": [
["...table_1.col1", "...table_2.col4"],
["...table_1.col1", "...table_2.col5"]
]
},
{
"urn": "...table_3...",
"hops": 2,
"paths": [
["...table_1.col1", "...table_2.col4", "...table_3.col7"]
]
}
]
Alternative: Lineage GraphQL API
While we generally recommend using the Python SDK for lineage, you can also use the GraphQL API to add and retrieve lineage.
Add Lineage Between Datasets with GraphQL
mutation updateLineage {
updateLineage(
input: {
edgesToAdd: [
{
downstreamUrn: "urn:li:dataset:(urn:li:dataPlatform:hive,logging_events,PROD)"
upstreamUrn: "urn:li:dataset:(urn:li:dataPlatform:hive,fct_users_deleted,PROD)"
}
]
edgesToRemove: []
}
)
}
Get Downstream Lineage with GraphQL
query scrollAcrossLineage {
scrollAcrossLineage(
input: {
query: "*"
urn: "urn:li:dataset:(urn:li:dataPlatform:hive,logging_events,PROD)"
count: 10
direction: DOWNSTREAM
orFilters: [
{
and: [
{
condition: EQUAL
negated: false
field: "degree"
values: ["1", "2", "3+"]
}
]
}
]
}
) {
searchResults {
degree
entity {
urn
type
}
}
}
}
Get Time-Filtered Lineage with GraphQL
Filter lineage edges by their last update time using lineageFlags:
query searchAcrossLineage {
searchAcrossLineage(
input: {
query: "*"
urn: "urn:li:dataset:(urn:li:dataPlatform:snowflake,analytics.orders,PROD)"
count: 10
direction: UPSTREAM
orFilters: [{ and: [{ field: "degree", values: ["1"] }] }]
lineageFlags: {
startTimeMillis: 1625097600000
endTimeMillis: 1627776000000
}
}
) {
searchResults {
entity {
urn
type
}
degree
}
}
}
This returns only upstream lineage edges that were last updated between July 1 and August 1, 2021.
FAQ
Can I get lineage at the column level?
Yes — for dataset-to-dataset lineage, both add_lineage() and get_lineage() support column-level lineage.
Can I pass a SQL query and get lineage automatically?
Yes — use infer_lineage_from_sql() to parse a query and extract table and column lineage.
Can I use filters when retrieving lineage?
Yes — get_lineage() accepts structured filters via FilterDsl, just like in the Search SDK.